




Elle ne s’affiche jamais, ne prend jamais la parole, et pourtant sans elle, des pans entiers du web resteraient muets. L’API REST agit comme une interface invisible, un trait d’union entre les applications, les données et les usages. Derrière sa façade technique se cache une architecture fine, rigoureuse, pensée pour durer. Décryptons ensemble ce qui fait d’elle bien plus qu’un simple outil : un fondement silencieux du numérique moderne.
Qu’est-ce qu’une API REST ?
Derrière l’acronyme REST – pour REpresentational State Transfer – se cache un style architectural qui a redéfini la manière dont les systèmes communiquent à grande échelle. Loin d’une simple convention technique, REST propose une philosophie d’échange, structurée, souple et conçue pour durer.
Ce paradigme voit le jour en 2000, dans la thèse de doctorat de Roy Fielding, alors co-auteur du protocole HTTP. Son ambition : formaliser un cadre d’architecture réseau capable de garantir scalabilité, interopérabilité et résilience dans des environnements distribués. L’idée maîtresse repose sur l’exploitation des méthodes HTTP standards (GET, POST, PUT, DELETE) pour interagir avec des ressources – des entités identifiables par une URL – plutôt que de recourir à des interfaces complexes ou propriétaires.
À rebours d’architectures plus rigides comme SOAP, REST parie sur la lisibilité et la simplicité d’usage. Il s’appuie sur quelques contraintes strictes (statelessness, cachabilité, séparation client/serveur…) qui, respectées, permettent de concevoir des systèmes légers, évolutifs et maintenables.
Les principes fondamentaux de REST
Les 6 contraintes du style REST
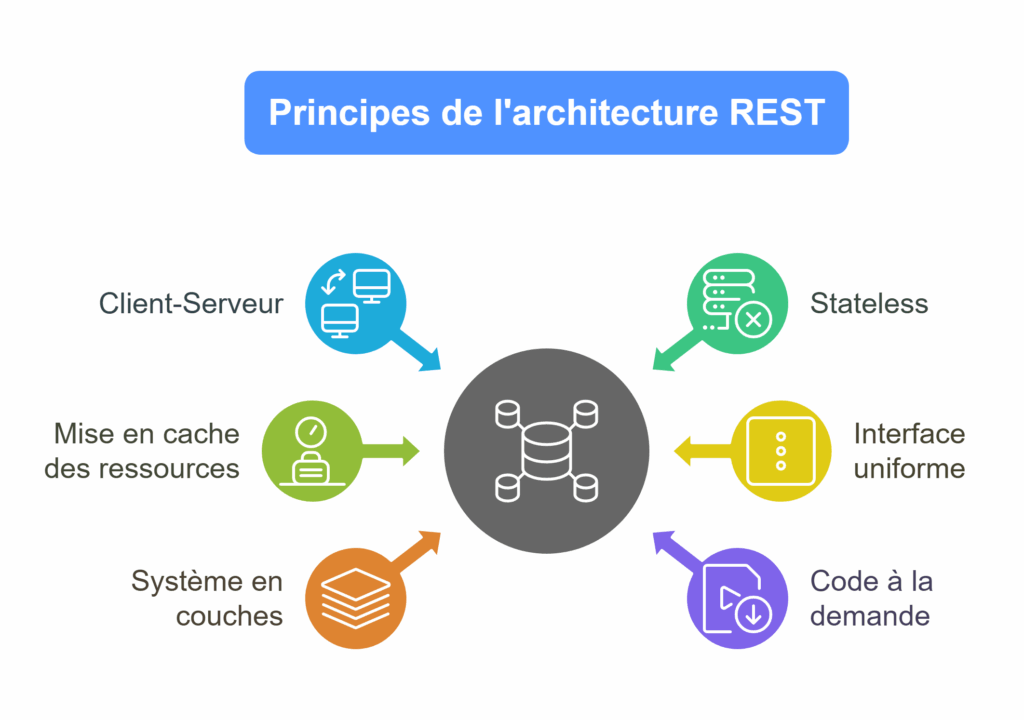
1. Client-Serveur
Le client et le serveur sont distincts et communiquent via une interface standard. Le client ne connaît rien de la logique interne du serveur.
👉 Exemple : une app mobile consomme une API sans connaître la technologie backend (Node, Django, Spring…).
2. Stateless
Chaque requête doit contenir toutes les informations nécessaires à son traitement. Le serveur ne conserve pas l’état des sessions entre deux appels.
👉 Exemple : une requête POST pour publier un article doit inclure l’identifiant de l’utilisateur, même s’il vient de se connecter.
3. Mise en cache des ressources
Les réponses doivent indiquer clairement si elles peuvent être mises en cache. Cela réduit la charge serveur et améliore les performances.
👉 Exemple : une requête GET vers /produits peut inclure un en-tête Cache-Control: max-age=3600.
4. Interface uniforme (Uniform Interface)
C’est le cœur du REST. Tous les échanges passent par une interface standardisée, avec des méthodes HTTP et des conventions claires.
👉 Exemple : un GET sur /utilisateurs/42 récupère l’utilisateur 42, quelle que soit l’app ou la plateforme.
5. Système en couches (Layered System)
L’architecture peut intégrer plusieurs niveaux intermédiaires (proxy, load balancer, CDN…) sans impacter le client.
👉 Exemple : un client peut interroger une API REST derrière un CDN, sans le savoir.
6. Code à la demande (optionnelle)
Le serveur peut fournir du code exécutable au client, comme du JavaScript. C’est la seule contrainte optionnelle.
👉 Exemple : l’API renvoie une fonction JS pour enrichir dynamiquement l’interface utilisateur.
Les méthodes HTTP et leurs usages
Les API REST exploitent les méthodes HTTP comme des verbes d’action. Chacune traduit une intention bien précise vis-à-vis d’une ressource. Un freelance qui les maîtrise évite les effets de bord et les comportements incohérents.
🔹 GET
Récupère une ou plusieurs ressources, sans effet de bord.
👉 Exemple : GET /articles/123 → récupère l’article 123.
🔹 POST
Crée une nouvelle ressource.
👉 Exemple : POST /articles avec un corps JSON → crée un nouvel article.
🔹 PUT
Met à jour l’intégralité d’une ressource.
👉 Exemple : PUT /articles/123 → remplace l’article 123.
🔹 PATCH
Modifie partiellement une ressource.
👉 Exemple : PATCH /articles/123 avec { « titre »: « Nouveau titre » }.
🔹 DELETE
Supprime une ressource.
👉 Exemple : DELETE /articles/123 → supprime l’article 123.
Chaque méthode doit respecter sa sémantique. Utiliser POST pour une mise à jour, ou GET pour supprimer, crée des comportements imprévisibles.
Les statuts HTTP : comprendre les réponses

Chaque requête reçoit une réponse structurée, accompagnée d’un code HTTP. Ce code, en trois chiffres, résume l’état de la transaction. Il sert à diagnostiquer un bug, afficher un message à l’utilisateur ou contrôler un flux métier.
📗 2xx — Succès
- 200 OK : la ressource a été retournée ou modifiée avec succès.
- 201 Created : une ressource a été créée (souvent après un POST).
📘 3xx — Redirection
- 301 Moved Permanently : la ressource a changé d’URL.
- 304 Not Modified : le client peut utiliser une version en cache.
📙 4xx — Erreur client
- 400 Bad Request : la requête est invalide (JSON mal formé, champ manquant…).
- 401 Unauthorized : authentification requise.
- 403 Forbidden : l’accès est interdit malgré une authentification valide.
- 404 Not Found : la ressource demandée n’existe pas.
📕 5xx — Erreur serveur
- 500 Internal Server Error : une erreur s’est produite côté serveur.
- 503 Service Unavailable : l’API est temporairement indisponible.
La bonne utilisation des statuts HTTP améliore la prédictibilité de l’API et facilite l’intégration côté client.
Cas d’usage des API REST
API REST dans le développement web
Dans les architectures web modernes, la séparation entre le frontend (l’interface utilisateur) et le backend (la logique métier) est devenue la norme. C’est précisément à ce carrefour que les API REST prennent toute leur valeur. Elles orchestrent le dialogue entre ces deux couches, de manière lisible, modulaire et indépendante de la technologie utilisée.
Prenons un exemple courant : une application construite en React côté client et en Node.js côté serveur. React envoie des requêtes HTTP (GET, POST, etc.) vers un backend Express qui expose des routes REST.
Ces routes retournent des données au format JSON, que React consomme et affiche dans l’interface. Cette structuration permet à chaque équipe de travailler sur son périmètre sans générer d’interférences, tout en garantissant une communication fiable et fluide.
REST devient alors un pont logique, un contrat implicite qui encadre les échanges et favorise une scalabilité sereine, même dans les équipes distribuées.
Intégration mobile
Côté mobile, les API REST jouent un rôle tout aussi stratégique. Que l’on développe pour Android avec Kotlin ou pour iOS avec Swift, l’enjeu reste le même : synchroniser l’application avec un serveur distant, dans un contexte souvent soumis à des contraintes de performance (réseau fluctuant, batterie limitée, stockage local).
Grâce à leur format léger (JSON via HTTP), les API REST réduisent l’empreinte réseau et facilitent la mise en cache ou le fonctionnement hors ligne. Les développeurs peuvent ainsi gérer finement les appels à l’API, afficher des contenus partiels ou différés, et synchroniser les données uniquement lorsque le réseau est disponible. Par ailleurs, REST simplifie l’intégration avec des SDK tiers ou des services cloud (Firebase, AWS, etc.), qui l’utilisent comme standard de communication.
Architecture microservices
Dans cet environnement fragmenté, les API REST deviennent l’adhésif structurant. Chaque microservice expose son propre point d’entrée via une API REST, ce qui permet aux autres services de le solliciter sans dépendance directe.
Ce découplage favorise l’autonomie des équipes, facilite la mise à l’échelle horizontale et renforce la résilience du système. En cas de panne d’un service, les autres continuent à fonctionner.
Des entreprises comme Netflix, Amazon, ou Spotify ont construit leur architecture autour de ce principe. REST y agit comme une langue commune, compréhensible par tous les services, quelle que soit leur technologie (Python, Java, Go…).
Comparaison avec d’autres styles d’API
REST vs SOAP
Face à REST, l’ancienne garde s’appelle SOAP (Simple Object Access Protocol). Ce protocole plus strict, basé sur XML, séduit encore certaines grandes entreprises, notamment dans la banque, l’assurance ou la santé, pour ses capacités avancées de sécurité, de vérification et de transactions distribuées.
Mais cette rigueur a un coût. SOAP impose une structure verbeuse, une configuration plus lourde, et un couplage fort entre client et serveur. À l’inverse, REST brille par sa légèreté, son interopérabilité naturelle avec HTTP, et sa prise en main rapide, notamment dans les projets modernes ou agiles.
REST vs GraphQL
Lancée par Facebook en 2015, GraphQL introduit une nouvelle manière de concevoir les échanges entre client et serveur. Là où REST impose un découpage rigide par ressource, GraphQL laisse le client choisir exactement les données qu’il souhaite recevoir – ni plus, ni moins.
Cette approche élimine deux problèmes fréquents avec REST :
- Le sur-fetching (récupérer trop d’infos inutiles),
- Le under-fetching (faire plusieurs appels pour reconstituer une vue).
Cela dit, GraphQL ne remplace pas REST : il le complète. Il exige un schéma strict, des résolveurs spécifiques côté serveur, et une complexité de mise en œuvre supérieure.
Pour une API simple, REST reste plus rapide à implémenter et plus intuitif. En revanche, dans un front complexe (tableaux dynamiques, dashboards, filtres imbriqués), GraphQL brille par sa souplesse.
Bonnes pratiques et pièges à éviter
Erreurs fréquentes à éviter
La première dérive concerne les codes de réponse HTTP. Trop de développeurs envoient systématiquement des 200 OK, y compris pour des erreurs ou des suppressions. Cela nuit au débogage, à la documentation et à l’expérience côté client.
Autre piège classique : des endpoints mal conçus, parfois ambigus (/getAllData, /doUpdate, /productAPI/endpoint1) ou non RESTful (/utilisateur/create au lieu de POST /utilisateurs). Ces déviations rendent l’API difficile à maintenir, surtout en équipe.
Enfin, certains oublient de valider les données reçues (body, params, query) ou retournent des messages d’erreur génériques. Résultat : les bugs remontent tardivement, voire jamais.
Tests et documentation
Une API REST sans documentation, c’est comme une gare sans panneau : tout le monde finit par s’y perdre.
Deux outils dominent le terrain professionnel :
- Postman : pour tester manuellement les endpoints, partager des collections, simuler des scénarios complexes.
- Swagger / OpenAPI : pour générer une documentation interactive à partir du code ou d’un schéma standardisé.
Le duo Postman + Swagger permet non seulement de vérifier le bon fonctionnement d’une API, mais aussi de rendre son usage transparent pour les autres développeurs, y compris côté client.
L’avenir des API REST à l’ère de l’intelligence artificielle
REST a traversé les modes et les évolutions du web. Pourtant, il entre désormais dans une nouvelle phase : celle de l’automatisation intelligente. L’essor des modèles d’IA générative comme GPT, ou des frameworks de décision autonomes, transforme peu à peu les usages liés aux API — y compris REST, pourtant si minimaliste par nature.
API REST et IA générative
L’intégration des modèles de langage comme ChatGPT ou Claude dans les workflows développeurs bouscule les pratiques.
Une IA peut désormais :
- Générer une documentation Swagger complète à partir d’un simple fichier de routes.
- Écrire des tests de requêtes Postman avec assertions dynamiques.
- Proposer une architecture REST initiale à partir d’un prompt métier.
Ce glissement de la technique vers la conversation intelligente ouvre de nouvelles perspectives, en particulier pour les développeurs. Ils peuvent accélérer leurs phases de prototypage, fiabiliser leur logique, ou mieux collaborer avec des équipes non techniques.
