



À l’heure où tout se digitalise, la cybersécurité est plus importante que jamais.
Qu’on parle d’une personne physique ou d’une organisation, l’utilisation des nouvelles technologies est de plus en plus courante et quotidienne (de la consultation des emails à la déclaration d’impôts), et leur sécurisation est primordiale.
Dans cet article, nous allons aborder les principales problématiques de cybersécurité, ainsi que les techniques de sécurisation d’un environnement web à travers l’exemple d’un back-end Node.js et du populaire framework Express.
Sécuriser son environnement back-end, en quoi c’est important ?
Le backend, dans une application web, c’est ce qui fait le lien entre un front (site web, application mobile, etc.) et la base de données. C’est par ici que se font notamment les requêtes de lecture et d’écriture des données ; assurer sa sécurité est donc essentiel.
Et même si protéger un environnement web à 100% est impossible, le rendre suffisamment sécurisé pour décourager les hackers est à la portée de tout développeur.
Cela est à la fois éthique mais relève aussi de la loi. Le RGPD (Règlement général sur la protection des données) impose par exemple des critères de sécurité des données.
Cela aurait pu éviter des piratages embarrassants, comme celui de Yahoo! en 2014, qui a avoué en 2016 s’être fait volé un milliard (!) d’identifiants.
Et si certains vols de données ont au final peu de conséquences (données inexploitables car chiffrées ou cachées), d’autres peuvent causer bien plus de mal (donnée bancaires accessibles, mots de passe en clair, etc.).
Les 6 techniques les plus courantes pour sécuriser son backend
Maintenant qu’on sait en quoi il est important de sécuriser un serveur back, voyons les techniques courantes que vous pouvez, en tant que développeur back end, mettre en place lors de votre développement.
1) Le chiffrement
Le chiffrement (aussi connu sous les termes – plus ou moins corrects – cryptage ou encryption) est une des bases à appliquer lorsqu’on parle de cybersécurité. Le cas typique de l’utilisation du chiffrement, c’est sur les mots de passe. Cela peut paraitre évident aujourd’hui, mais il reste beaucoup trop de bases données en ligne avec les mots de passe stockés en clair… Il suffit qu’une de ces bases soit récupérée pour obtenir tout un tas de correspondances email-mot de passe, probablement valides ailleurs sur le web.
Pour chiffrer un mot de passe, on va utiliser une fonction de hachage. Si l’on utilisait avant les algorithmes comme MD5 ou SHA-2, il est aujourd’hui d’usage d’utiliser Bcrypt. Avec Node.js, on va d’ailleurs utiliser directement le module éponyme pour l’intégration de cette fonction.
2) Le salage
Le salage est une technique de sécurisation bien connue, qui est d’ailleurs nativement utilisée par Bcrypt. Pour faire simple, il suffit de rajouter un « sel » (un ou une suite de caractères) à la donnée que l’on veut chiffrer, de manière à stocker une donnée différente de ce que pourrait saisir l’utilisateur ; comme son mot de passe.
Prenons un exemple d’un utilisateur ayant pour mot de passe 1234. Le back-end du service qu’il utilise chiffre les mots de passe avec SHA-256, ce qui retourne la valeur suivante :
a665a45920422f9d417e4867efdc4fb8a04a1f3fff1fa07e998e86f7f7a27ae3
On va donc utiliser la technique du salage, et ajouter une chaine de caractères au mot de passe de l’utilisateur avant que celui-ci ne soit chiffré. Imaginons que le sel soit salty. Le mot de passe qui sera stocké dans la base sera alors le chiffrement de « 123salty« , soit :
f735b0aa7185e09773d4de77812db2cfe2b9614d6b10963a003c98a9d0ed38e0
Deux chaines de caractères différentes, donc.
L’intérêt du salage est multiple, il permet de lutter contre les attaques par analyse fréquentielle, les attaques utilisant des rainbow tables, les attaques par dictionnaire ainsi que les attaques par force brute.
3) La limitation les données stockées
S’il est des données que nous devons enregistrer en base (login, mot de passe, etc.), il vaut mieux limiter le nombre d’informations stockées. Si jamais votre base tombe entre les mains de hackers, moins d’informations ils auront, moins ils pourront faire de choses avec les données récupérées.
Cela veut dire dans un premier temps ne pas stocker de données inutiles. Mais on peut aller plus loin et également faire en sorte de ne pas stocker entièrement certaines données.
Par exemple, pour une date de naissance, on pourrait ne stocker que le mois et l’année et non pas le jour. Ainsi, ce seront des données suffisantes pour vérifier l’identité de l’utilisateur (si couplée à d’autres données), mais elles seront inutilisables si jamais la base tombe entre de mauvaises mains.
4) Le masquage des données
Et pour les données qu’on doit forcément stocker, il y a aussi la possibilité de les masquer, totalement ou en partie.
Par exemple, certains développeurs back choisissent de chiffrer, en plus du mot de passe, d’autres données, comme par exemple l’adresse email (en utilisant une autre techno de chiffrement). Ces données sont ainsi stockées masquées dans la base qui devient rapidement inutilisable en cas de récupération.
5) L’utilisation du json web token
Parmi les classiques de la sécurisation d’un backend, on retrouve évidemment les token d’authentification. Par exemple, pour Node.js, la librairie jsonwebtoken est devenu un standard (plus de 6 millions de téléchargements par semaine !).
Comment ça fonctionne ? À la connexion d’un utilisateur, le backend va générer un token : un ensemble de données chiffrées via une clé privée, avec une éventuelle durée de validité. Ce token va être envoyé au front et y être stocké.
Lorsque l’utilisateur va faire une requête au serveur, il va renvoyer ce token, ainsi que des données qui permettront d’authentifier sa requête (son id, par exemple). Le serveur, connaissant la clé privée, va décoder le token et vérifier que les datas qui y sont stockées sont bien celles attendues (il peut notamment les comparer à l’id de l’utilisateur) et accepter ou refuser la requête.
Par exemple :

Ici, via la librairie jsonwebtoken, on crée un token contenant un objet simple ({data: foobar}) chiffré grâce à la clé ‘secret‘ et expirant une heure après sa création. Le token généré va être renvoyé au client.
Lors d’une requête, il va être renvoyé, et le serveur va vérifier son authenticité et sa validité grâce à la méthode ‘verify‘:

Ainsi, si les données récupérées (foobar) ne correspondent pas à ce qui est attendu, le serveur va rejeter la requête.
6) L’authentification à double facteurs
Une dernière action qu’on peut mettre en place pour sécuriser un serveur back, c’est l’authentification à double facteurs. C’est devenu presque une norme sur les gros sites (Facebook, Google, etc.) ou ceux nécessitant un niveau de sécurité supplémentaire (banque, etc.).
Vous savez comment ça marche, il s’agit de rajouter une étape à la connexion, soit après un certain temps sans s’être connecté, soit lorsque la connexion se fait depuis un nouvel appareil. On demandera à l’utilisateur de confirmer son identité via un code, envoyé par sms ou par email. Voire par la poste, comme le fait (ou l’a fait) La Banque Postale avec son certicode…
Utiliser des packages npm pour sécuriser son serveur
Voilà, on a fait le tour des éléments plus ou moins classiques à mettre en place sur un serveur back end Node pour assurer un certain niveau de sécurité.
Mais, on peut encore faire plus, et très simplement, via l’utilisation de middlewares. Faisons le tour de quelques-unes de ces librairies utiles et faciles à mettre en place.
helmet
helmet est un middleware permettant d’ajout de la sécurité à un serveur Express. Via la simple inclusion de la ligne de code suivante :
app.use(helmet());
helmet ajouté en réalité 11 petites librairies internes. Pour en savoir plus sur ce package, rendez-vous ici.
maskdata
maskdata est une librairie permettant de très facilement masquer des données via des patterns prédéfinis. Numéros de téléphone, cartes de paiement, adresses email… maskdata transforme des chaines de caractères claires en d’autres, lisibles mais non identifiables.
Par exemple, pour masquer une adresse email :

Ou un numéro de téléphone :
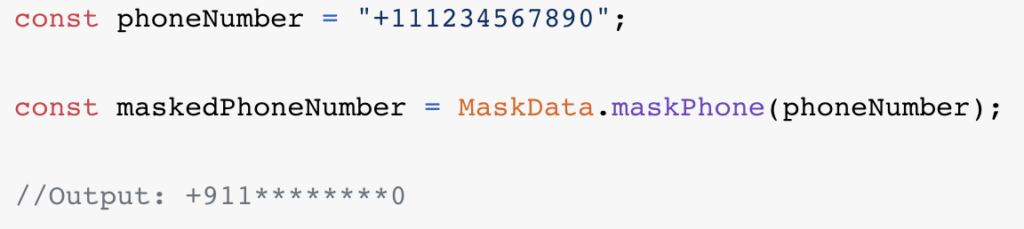
L’idée, c’est de ne pas renvoyer au front les données en clair, mais masquées. Cela a deux avantages :
- Les données transitent cachées dans les flux réseaux ;
- Elles sont illisibles pour toute autre personne que celle à qui elles appartiennent.
C’est notamment employé pour l’authentification à double facteurs. Sur votre écran sera écrit de rentrer le code reçu sur votre mobile au numéro X, numéro étant partiellement masqué. Cela empêcherait un éventuel usurpateur d’avoir votre numéro de téléphone de cette manière.
Voir la documentation ici.
express-rate-limit
Un dernier middleware qu’il est intéressant d’utiliser pour sécuriser un back-end Node, c’est express-rate-limit. Comme son nom l’indique, il permet de limiter le nombre de requêtes envoyées vers un serveur Express.
L’utilité, c’est d’éviter d’une API soit appelée des centaines de fois depuis la même adresse IP, surtout lorsqu’il s’agit d’une API sensible (création de compte, modification de mot de passe, etc.)
Concrètement, ça se présente comme ça :

Comme on le voit, on limite ici le nombre d’appel à l’API de création de compte à 5 par heure et par adresse IP.
Pour en savoir plus sur ce middleware, ça se passe ici.
Conclusion
Comme on l’a vu, lorsqu’on développe une application web, sécuriser le back-end et la base de données, c’est primordial. Des données sensibles peuvent y être stockées, et les exemples de piratages sont légions. Il vaut donc mieux prendre ses précautions.
On l’a dit, il y a plusieurs moyens de sécuriser son backend, certains plus faciles à mettre en place que d’autres, mais il reste important d’ajouter autant de sécurité que possible – bien que cela dépende de la sensibilité des données stockées.
Avez-vous déjà eu à sécuriser un back-end Node.js ? Quelles techniques avez-vous utilisées ? Dites-le en commentaire !
