




Imaginez un orchestre où chaque musicien joue au bon tempo, mais où le chef d’orchestre se trompe dans ses instructions. Résultat ? Un chaos sonore inefficace. C’est exactement ce qui se produit lorsque des requêtes SQL mal optimisées pilotent vos bases de données. Temps d’attente interminables, serveurs surchargés, et budgets qui explosent : la symphonie tourne au fiasco.
Cet article vous montre comment reprendre la baguette et orchestrer vos requêtes SQL avec précision. Nous explorerons les bases pour comprendre comment les requêtes fonctionnent en coulisse, puis nous vous donnerons des techniques concrètes pour optimiser votre code, gérer vos ressources efficacement et intégrer des solutions applicatives adaptées.
En avant ! Partons à la découverte des clés pour écrire des requêtes SQL à la fois performantes et optimisées.
Les bases des requêtes SQL expliquées
Les requêtes SQL suivent un processus bien défini : elles sont d’abord analysées et compilées par le moteur de la base de données. Ce dernier vérifie la syntaxe et génère un plan d’exécution, une sorte de feuille de route décrivant les étapes nécessaires pour exécuter la requête de manière optimale.
Ensuite vient la phase d’exécution, où les instructions sont traduites en actions concrètes : accéder aux tables, filtrer les données, et renvoyer les résultats. Comprendre ce processus aide à repérer les points d’amélioration et à éviter des étapes inutiles.
SQL propose quatre grands types de requêtes :
- SELECT pour extraire des données.
- INSERT pour ajouter des informations.
- UPDATE pour modifier des enregistrements.
- DELETE pour les supprimer.
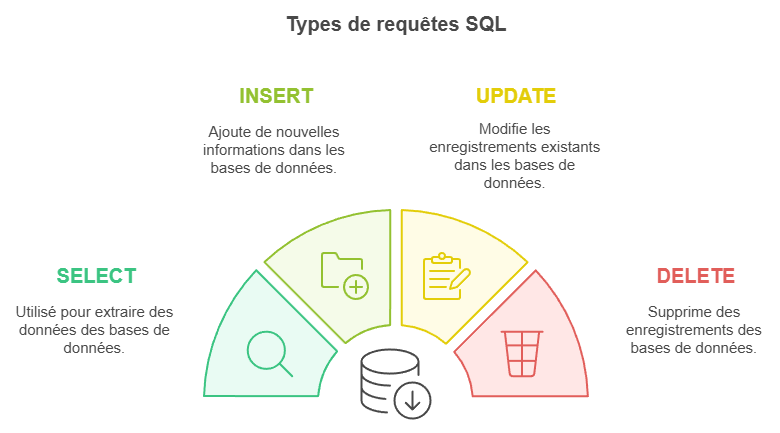
Chaque type répond à des besoins spécifiques, mais leur efficacité repose parfois sur des structures avancées :
- Jointures : elles combinent des tables pour croiser des données liées, idéales pour des analyses complexes.
- Sous-requêtes : qui permettent d’extraire des données à inclure dans une requête principale, mais doivent être utilisées avec parcimonie pour éviter les ralentissements.
- Vues : ces dernières offrent une perspective simplifiée sur des tables complexes, facilitant la réutilisation et la clarté des requêtes.
Maîtriser ces concepts est un premier pas vers une optimisation réussie. Passons maintenant à des conseils concrets pour améliorer vos requêtes SQL.
1️⃣ Optimisation au niveau du code SQL
Choisir les bonnes colonnes et éviter le « SELECT * »
L’utilisation de SELECT * est une erreur courante qui entraîne un transfert inutile de données entre le serveur et le client.
Cette pratique consomme inutilement des ressources, en particulier lorsque la table contient de nombreuses colonnes inutiles pour l’analyse. Il vaut mieux privilégier une sélection explicite des colonnes nécessaires, ce qui réduit la quantité de données transférées et améliore les performances globales.
Utiliser des clauses filtrantes efficaces (WHERE, HAVING)
Les clauses WHERE et HAVING permettent de restreindre les données traitées par vos requêtes. Toutefois, leur efficacité dépend des conditions employées.
Par exemple, évitez les opérateurs logiques tels que OR lorsque des index peuvent être exploités avec des conditions basées sur AND.
De plus, structurez les filtres en veillant à ce que les colonnes utilisées soient indexées et que les comparaisons évitent des conversions inutiles (comme des types différents).
Éviter les requêtes imbriquées redondantes

Les sous-requêtes, bien que pratiques, peuvent nuire aux performances lorsqu’elles sont mal employées.
Dans la plupart des cas, les jointures (JOIN) sont une alternative plus rapide et plus efficace, car elles permettent au moteur de la base de données d’optimiser l’exécution via le plan d’exécution.
Par exemple, remplacer une sous-requête dans une clause WHERE par une jointure réduit souvent les calculs redondants.
Optimiser les jointures
Les jointures, justement, sont fondamentales, mais leur efficacité dépend de l’ordre des tables et de la structure de la requête. Il faut privilégier des jointures internes (INNER JOIN) lorsque possible, car elles sont plus rapides que les jointures externes (OUTER JOIN).
Par ailleurs, placez les tables contenant les plus petits ensembles de données en premier dans l’ordre des jointures pour minimiser le traitement initial.
En appliquant ces pratiques, vous pourrez réduire la latence, augmenter la fluidité des transactions et exploiter pleinement la puissance de vos bases de données.
2️⃣ Gestion des ressources au niveau de la base de données
Partage et partitionnement des tables
Le partitionnement des tables est une solution clé pour gérer efficacement des volumes importants de données. Il existe deux approches principales :
- Partitionnement horizontal : les données sont divisées en fonction des lignes, par exemple par date ou par région, ce qui permet de travailler sur des segments spécifiques sans charger l’ensemble de la table.
- Partitionnement vertical : ici, ce sont les colonnes qui sont réparties, regroupant celles qui sont souvent utilisées ensemble. Cela réduit la charge lorsque seules certaines colonnes sont nécessaires dans les requêtes.
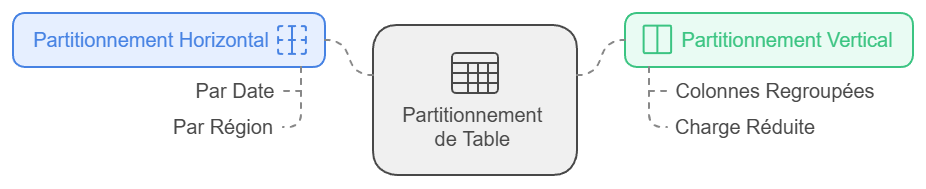
Ces techniques améliorent la performance globale et facilitent la scalabilité.
Surveiller les statistiques et les plans d’exécution
L’optimisation passe par une analyse approfondie des requêtes exécutées.
Les commandes EXPLAIN et EXPLAIN ANALYZE offrent une vue détaillée du plan d’exécution choisi par le moteur de la base de données. Elles permettent d’identifier les goulets d’étranglement comme des scans de table complets ou l’absence d’index adéquats.
En interprétant ces informations, vous pouvez ajuster les requêtes ou les structures des tables pour une meilleure performance.
3️⃣ Améliorer les performances au niveau applicatif
Privilégier les requêtes préparées
Les requêtes préparées jouent un rôle central dans l’optimisation des bases de données en réduisant la charge liée à la compilation.
En effet, lorsqu’une requête est préparée, le moteur de la base de données crée un plan d’exécution une seule fois, puis l’exécute plusieurs fois avec des paramètres différents.
Cette approche minimise la latence, surtout dans les scénarios où des requêtes similaires sont exécutées fréquemment, comme les applications interactives ou les rapports dynamiques.
Éviter les requêtes répétées
Les appels redondants à la base de données peuvent considérablement ralentir une application. L’utilisation de systèmes de cache comme Redis ou Memcached permet de conserver temporairement des résultats fréquemment utilisés en mémoire.
Ces outils réduisent le nombre de requêtes envoyées à la base de données, accélérant ainsi les performances globales tout en diminuant la charge sur les serveurs.
Cette stratégie est particulièrement utile pour les données statiques ou peu fréquemment mises à jour.
Gestion des transactions
Les transactions SQL garantissent la cohérence des données, mais elles peuvent introduire des problèmes de performance si elles verrouillent les ressources trop longtemps.
Pour éviter les conflits, il est essentiel de limiter la durée des transactions et de réduire leur portée. Par exemple, privilégiez les niveaux d’isolation adaptés (comme READ COMMITTED plutôt que SERIALIZABLE) et découpez les transactions complexes en opérations plus simples.
Une gestion fine des verrous améliore à la fois la fluidité des opérations et l’expérience utilisateur.
Minimisation des appels à la base de données
Une technique efficace consiste à effectuer des agrégations ou traitements côté serveur avant de transmettre les résultats à la base de données. Cela limite le volume de données échangées et diminue le temps de réponse.
Par exemple, on peut calculer des totaux ou regrouper des informations directement dans l’application avant d’interagir avec la base.
Conclusion
Ces bonnes pratiques, loin d’être anodines, redéfinissent les standards d’efficacité et de performance, essentielles dans un monde où l’information est le cœur des décisions. Dès lors, penser SQL, c’est penser innovation et durabilité, un défi que les entreprises doivent désormais embrasser pour prospérer dans une ère numérique en perpétuelle effervescence.

